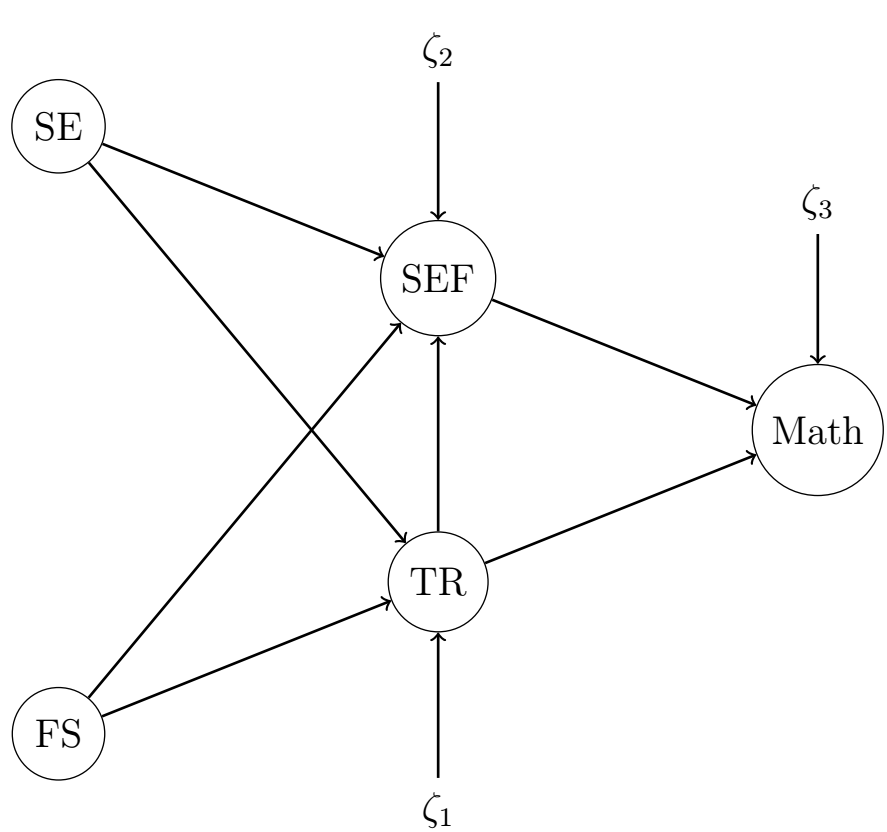
model<-'#measurement model SEF=~SEF1+SEF2+SEF3TR=~TR1+TR2+TR3+TR4+TR5SE=~SE1+SE2+SE3+SE4+SE5FS=~FS1+FS2+FS3+FS4+FS5TR~g11*SE+g21*FSSEF~g12*SE+g22*FSMath~b1*SEF+b2*TRI11:=g11*b1I21:=g21*b1I12:=g11*b2I22:=g21*b2'fit<-sem(model,data=df)summary(fit)
In this part, we forget the structural model and we focus only on the measurement model. The first question is to check that the measures of the latent variables are consistent with the way the researcher understands those latent variables (e.g. we check that the items SEF1, SEF2, SFE3 are really associated with SEF).
model0<-'#measurement model SEF=~SEF1+SEF2+SEF3TR=~TR1+TR2+TR3+TR4+TR5SE=~SE1+SE2+SE3+SE4+SE5FS=~FS1+FS2+FS3+FS4+FS5'
This is conformatory factor analysis (CFA).
fit0<-cfa(model0,data=df,meanstructure=T)
The consistency of the construction of latent variable is based on GOF indices, we must have
All the issues of this section are extracted from .
Let’s look at the question of the difference in self-efficacy feeling between boys and girls. The most common way to do this is to compare group means by a Student test. But, this requires that
boys and girls understand and react similarly to the questions,
the response models should be invariant across gender.
To assess these assumptions, the measurement models are tested against an increasing number of constraints. All these models are nested.
Fisrt step: Configural model. The invariance of the model form is checked: do the latent variables follow the same pattern across genders? (i.e. same items are associated with same latent variables for boys and girls).
According to the criteria defined above for the GOF indices, this model is acceptable. However, it is necessary to check that it fits the data as well as the model without gender. As these two models are nested, the difference between them can be assessed on the basis of the significance of the change in \(\chi^2.\).
lavTestLRT(fit0,fit_config)
However, as usually this test is sensible to the sample size, thus alternative fit indices comparisons are used in application. The differences in CFI (\(\Delta CFI\)) and RMSEA (\(\Delta RMSEA\)) are the most commonly used and may not exceed 0.01 in absolute value.
For all the latent of the configural model, the following diagram describes the measurement model:
Second step: Weak invariance (or metric invariance). If weak invariance is supported, the equivalence of the item loadings on the latent variable is tested. Metric invariance means that each item contributes to the latent construct to a similar degree across groups. With previous notations the null hypothesis is \[
\begin{cases}
\lambda^g_1=\lambda^b_1, \\
\lambda^g_2=\lambda^b_2, \\
\dots
\end{cases}
\]
Third step: Strong invariance (or scalar invariance). If weak invariance is supported, the equivalence of the item intercept on the latent variable is tested. Scalar invariance means that mean differences in the latent construct capture all mean differences in the shared variance of the items. With previous notations the null hypothesis is
Strong invariance cannot be supported. To improve the fit of the model, we can assume that strong invariance is true, with the exception of some items that need to be identified.
In this section we look for gender invariance in the mediation model examined above. More specifically, is this mediation model the same for male and female students?
model0<-'# measurement model SEF=~SEF1+SEF2+SEF3TR=~TR1+TR2+TR3+TR4+TR5SE=~SE1+SE2+SE3+SE4+SE5FS=~FS1+FS2+FS3+FS4+FS5# structural modelSEF~SE+FSTR~SE+FSMath~SEF+TR# constraintTR~~0*TR'fit0<-sem(model0,data=df,group="gender",group.equal=c("loadings","intercepts","regressions"),group.partial=c("SE2~1","SE4~1"))fit1<-sem(model0,data=df,group="gender",group.equal=c("loadings","intercepts"),group.partial=c("SE2~1","SE4~1"))lavTestLRT(fit0,fit1)
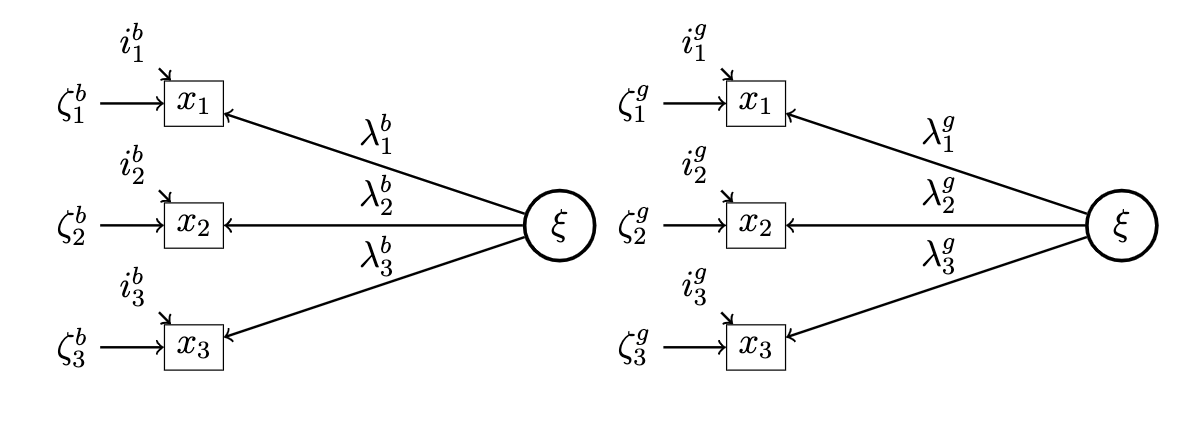 Second step: Weak invariance (or metric invariance). If weak invariance is supported, the equivalence of the item loadings on the latent variable is tested. Metric invariance means that each item contributes to the latent construct to a similar degree across groups. With previous notations the null hypothesis is
Second step: Weak invariance (or metric invariance). If weak invariance is supported, the equivalence of the item loadings on the latent variable is tested. Metric invariance means that each item contributes to the latent construct to a similar degree across groups. With previous notations the null hypothesis is